


AI Data Analytics - Datawisp vs. the Big Players
Note: this article is modified from the original Oct 2nd version. We've updated the benchmark results to include Databricks Genie instead of the Assistant since it performs significantly better and is Databricks' designated "natural language to insights" solution. We also updated the scores to reflect Datawisp being graded manually by our data scientist instead of using our automated benchmark - the automated benchmark was designed internally to speed up the process and uses AI to grade the AI's results. Now all scores reflect the same methodology.
Overview
With all the hype around AI and the fact that every data company uses the same exact words to describe its products, it can be really hard to distinguish marketing fluff from real performance. Just go to any data convention exhibit floor and you’ll see swaths of booths plastered with the same promises of making your company more “data driven” and “increasing efficiency.” Datawisp is no exception - admittedly we’re also guilty of using some of the same language as everyone else: “ask any question in natural language and get an answer in under five seconds.” Right.
So how well do these products actually work? We put Datawisp head to head with products made by some of the biggest companies in BI and shot them out ourselves to save you time (foreshadowing: this took an incredible amount of time). We included:
Thoughtspot Sage
Microsoft PowerBI + Copilot
Amazon Quicksight + Q
Databricks Genie*
Snowflake Copilot*
These platforms all make the same promise of taking questions asked in natural language and delivering charts and tables, so we felt the comparison was a fair one.
*Note that if your data is stored somewhere else (say BigQuery), you'll have to use a third party connector to get it into Databricks/Snowflake, which can be quite a hassle and probably out of scope for someone just shopping for a BI tool.
Here’s what we found.
Quantitative benchmark scores
Our benchmark has 30 different questions that range in complexity and clarity (how well the question is written) and that are accompanied by a series of matching datasets. We fed all the necessary data into each platform then asked all 30 questions and graded the responses (we describe our methodology in full later on). Here’s how the platforms performed:


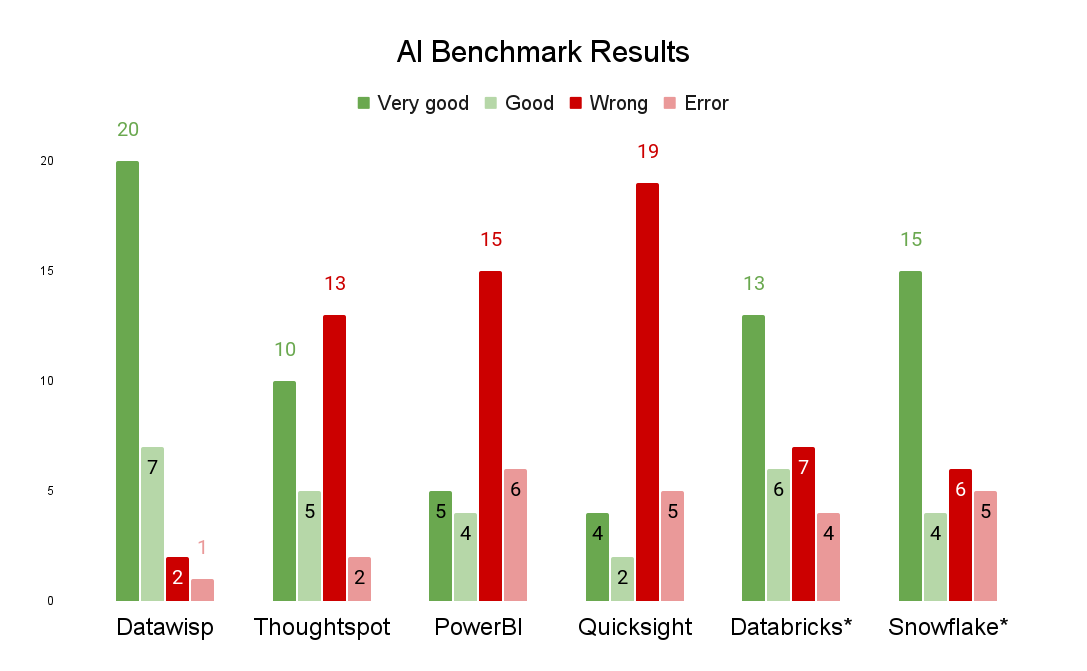
Datawisp: 20/7/2/1
Thoughtspot Sage: 10/5/13/2
PowerBI + Copilot: 5/4/15/6
Quicksight + Q: 4/2/19/5
Databricks Genie: 13/6/7/4
Snowflake Copilot: 15/4/6/5
Immediately, you’ll notice that Datawisp had both the most correct answers and, just as importantly, the fewest (by far) incorrect answers. While we don’t want to speculate as to how the other products work (they’re essentially black boxes), we have an idea of why performance looks like this, which we’ll get into in more detail.
Testing methodology
We built our benchmark with the help of a third party data scientist during the development of Datawisp to measure changes in performance resulting from tweaks to our AI logic. The questions we used were based on questions that we encountered while talking to clients, and in general, a higher benchmark score often led to better performance with real-life client data. Therefore we’re confident that this benchmark is a reasonably unbiased test of an AI powered analytics tool’s ability to answer client questions - even if we had a hand in developing it ourselves.
Benchmark materials:
We manually graded each answer according to these criteria:
Very good: a perfect answer
Good: a mostly correct answer
Incorrect: a wrong answer
Error: The tool either gave no result or the question caused it to crash/error
Quantitative results analysis
Correct and semi correct answers
Datawisp had the highest number of correct answers. Snowflake and Databricks performed comparably to each other and did reasonably well. The others were very poor in our testing.
Quicksight and Powerbi mainly work as data visualization tools meant to be used by data scientists - with AI later added on as an extra (this is apparent in many places, including usability and customer support which we’ll discuss). They expect data scientists to manipulate data using SQL before they bring it in for the visualization stage, and therefore the AI powering the data visualization tool doesn’t have the full set of features it needs in order to answer the questions completely. The way the end user can slice and manipulate the data is somewhat limited in traditional BI applications. Integrating AI into these tools means the AI is limited in the same way. The end result is AI that can save a BI user a few clicks but isn’t very powerful on its own.
Thoughtspot claims to be AI native, so we're not quite sure why its performance was so bad. It seems unable to transform data in the necessary way to answer most questions; that restriction seems self-imposed rather than by design.
Databricks and Snowflake performed better, perhaps because they work by directly translating the user's question to SQL and aren't limited in the way the others are. It's impossible to know exactly how they work, but our theory is that those solutions skip some of the reasoning steps we've built into Datawisp.
Incorrect answers and errors
Datawisp has the fewest number of incorrect answers and errors as well. We think this is mainly due to three things:
Logic: we’ve spent a lot of time iterating on our AI’s logic to make sure that it takes many of the same steps that a data scientist would take - evaluating the data, formulating a query, checking its work, etc.
Datawisp blocks: our proprietary blocks act as guardrails and ensure that any code the AI writes can produce a sensible output. Datawisp first takes the AI generated code and translates it into Datawisp blocks, then compiles those blocks into SQL and runs the query on the database. If either code fails to run, the AI can re-attempt to solve the issue slightly differently.
Datawisp is designed for non-technical users who can’t tell the difference between a right and wrong answer - so it attempts to avoid incorrect answers even at the cost of delivering the best possible answer in some cases (why it has so many partially good results).
At Datawisp, we think minimizing incorrect answers are key to building a reliable, trustworthy data platform that everyone across the enterprise can confidently rely on to answer questions.
We spent a lot of time testing all of these solutions and took notes throughout the process. Here’s some insights we collected about each platform while going through the benchmark questions:
Thoughtspot
Thoughtspot’s AI feels more native to the product, not “glued on” like the others on the list - even if the quality of the AI itself leaves something to be desired. The results were disappointing even for some very simple questions. Sage (the AI) tries to explain its logic but doesn’t do so as well as the other products and when it fails it doesn’t really provide any actionable next steps.
Example: What is the most common number of payment installments for payments over $500


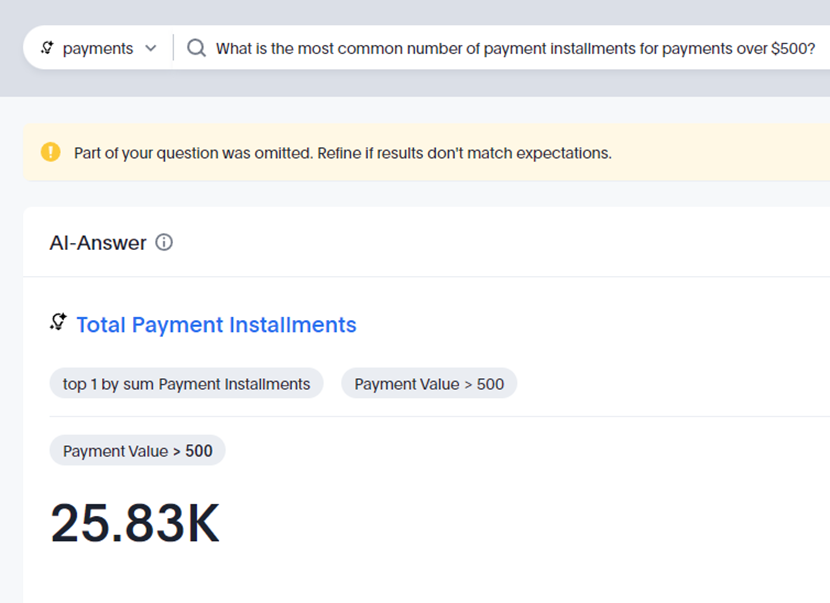
PowerBI
PowerBI seems to favor erroring over giving wrong / incomplete answers - it had far more errors than the alternatives, although at least its error messages were understandable.
Example: Which products are frequently bought together?
Power BI Q&A does not support identifying frequently bought together products directly. However, you can analyze the dataset to find patterns of products that are often purchased in the same order. This typically involves more advanced data analysis techniques such as market basket analysis or association rule mining, which are not supported here.
Due to technical limitations, such as only being able to join on one column and not supporting multiple aggregations, PowerBI was unable to answer more complex questions, and this was reflected in its score.
Quicksight
The most disappointing platform we tested. Its weak AI (Q) was unable to meaningfully transform data, offered very little help getting datasets organized and joined, and created only passable charts when it did get an answer. The AI does share its interpretation of the question asked, but most of the time the only use for that is to see how poorly Q understood the question:
Example: How many different products have a freight value more than half of the price?
Interpreted as: Unique number of Product Id where Freight Value is more than 50.
Without even understanding the question, answering it becomes impossible.
Databricks
Databricks Genie performed relatively well. It was able to seamlessly handle joins, unlike some of the other tools. While it favored incorrect answers over errors in our sample, it did so at a lower rate than most. For questions it wasn't able to get right, Genie provided satisfactory explanations.
Snowflake
Despite technically not meeting the criteria for selection (must be strictly natural language to insights BI tool), we ran Snowflake’s solution (Snowflake + Copilot) through our benchmark anyway. This is a more technical product intended to be used by data scientists and while it does take questions in natural language, its output is always SQL, not a table, chart, or number. Snowflake does give the option to run the SQL in a notebook, but it’s not done automatically.
Similar to Databricks, the text-to-SQL approach gave better answers. For data scientists that can quickly identify wrong answers, it's a good solution that we'd recommend trying. For non data professionals, we felt that providing SQL could lull users into a false sense of security.
User experience and other qualitative metrics
We also compared our experience of working with these tools relative to Datawisp and found they differ greatly in usability. We graded them 1 (bad) through 5 (great) on ease of getting started, usability, AI-made charts, cost / cost transparency, and support.
Thoughtspot Sage
Getting Started: 4
Support: 3
UI/UX: 2
AI Charts: 4
Cost/transparency: 4
Documentation: 3
Notes: Thoughtspot is the smallest company on this list. The product is cheaper and much easier to get started with than its competitors. However, its UI is not particularly intuitive (things move unexpectedly) and the AI is fairly weak. It answers very simple, straightforward questions well as long as your data is clean. Pricing is fairly reasonable and straightforward, and we never needed to talk to their support. Since there isn’t much friction, we recommend trying it to see if it works for you.
PowerBI + Copilot
Getting Started: 1
Support: 2
UI/UX: 5
AI Charts: 2
Cost/transparency: 2
Documentation: 1
Notes: PowerBI is free to download, but getting access to Copilot required much more work. After failing to turn it on ourselves, we reached out to support, which recommended a completely different product to us that didn’t meet our requirements (ML Workbench). When pressed further, we were sent to a 3rd party vendor, who quoted us a $5k+ option initially, before we were able to figure out a workaround and pay for Fabric and Copilot per hour through an Azure subscription. Unless you’re a big enterprise client and have an existing relationship with Microsoft, getting Copilot to work with PowerBI is a huge pain in the ass.
QuickSight + Q
Getting Started: 2
Support: 2
UI/UX: 1
AI Charts: 3
Cost/transparency: 2
Documentation: 3
Notes: We cannot in good conscience recommend this to anyone. It’s difficult to set up and doesn’t work out of the box with other AWS products (RDS postgres); we had to meet with our AWS rep to ask for a trial, and our CTO had to build a workaround to get Quicksight to see our data in AWS. The AI performance is subpar and doesn’t make up for any of these other shortcomings. Support wasn’t particularly helpful and pricing is a mess of various monthly fees that enable certain parts of the product and other usage-based fees.
Databricks Genie
Getting Started: 2
Support: 4
UI/UX: 3
AI Charts: 4
Cost/transparency: 3
Documentation: 2
Notes: Genie actually wasn't mentioned by the first team we spoke to at Databricks, as it's in public preview. This is why we initially benchmarked Databricks Assistant (which performed much worse). With a bit more documentation and visibility it would score a lot higher.
Databricks requires a connection to a cloud provider on signup, and needs admin access to your cloud dashboard. Once this is done, getting started is fairly straightforward. Cost, however, isn’t very clear as it’s consumption based. Ask the wrong questions and your bill might skyrocket. But they do show you how to calculate cost.
Snowflake Copilot
Getting Started: 3
Support: 4
UI/UX: 3
AI Charts: 0
Cost/transparency: 3
Documentation: 3
Notes: Since we have an existing relationship with Snowflake, our rep was able to get us started with Snowflake’s Copilot fairly quickly, but it did require setting up a call where they tried to upsell us on various other features and “learn more about our business.” Since Copilot doesn't actually produce charts (it writes SQL), we had to give it a zero for charting. Pricing is a complex equation based on credit usage, and Copilot is wrapped into this.
The elephant in the room
Where’s Tableau in all of this? Why didn’t we test the biggest name in BI?
Frankly, we tried. While we were able to get Tableau running just fine, Einstein (Tableau’s AI) is only available for enterprise clients. We spent over two weeks going back and forth with different folks at Salesforce from sales to tech support, and as of the writing of this article, we still haven’t heard back, despite being promised a trial.


Note: after waiting over 2 weeks, we were eventually told that we wouldn't be able to get a trial at all.
TL;DR
Some of these products are simply traditional BI tools with AI sprinkled on. They just weren’t designed to be asked questions in natural language. That's pretty obvious from the benchmark scores. Microsoft, Salesforce, etc. already have huge client bases that depend on these products, and they can’t freely make radical changes to them without upsetting a lot of folks.
Datawisp, on the other hand, was built specifically to be used in this way. It shows not only in the number of correct answers but also in the low number of errors and wrong answers. Text-to-SQL can be very powerful, as Databricks and Snowflake showed us, but balancing performance and reliability is hard. We think we’ve built something incredible that businesses can rely on today, and will only continue to improve over time. We'll also continue pushing for transparent benchmarks that help us measure performance in an objective way.