


How GenAI Will Finally Allow Data Companies to Scale
Most data products promise big things: “Transform your business to be data-driven! Add value across your organization! Make every single decision better!” But why do BI tools struggle to scale beyond a certain point?
Tableau was acquired by Salesforce in 2019 for $15.7 billion, while Slack was acquired (also by Salesforce) in 2021 for nearly twice that amount. Amplitude is currently valued at $1.3 billion, whereas Zendesk, a platform for support tickets, is worth $9.5 billion—more than seven times as much. If data is so valuable, then why this disparity?
The answer is simple: Slack and Zendesk create value for almost every employee or customer. Data tools, in contrast, don’t create nearly as much value as we think. They can only be used by very few people within the organization and have little pricing power left. This is because:
Current-generation BI tools (those developed before the advent of LLMs) are restricted in what they can do and who they can serve
Their core functions have become less technically challenging due to modern infrastructure tooling (e.g., dbt), which has led to pricing pressure from cheaper competitors
This article will discuss the limitations of current-gen data products and how genAI can overcome these limitations to deliver on the promises of “democratizing access to data” that we’ve all heard so many times.
Just Adding AI Doesn’t Work
Broadly speaking, there are two types of data tools:
Generic BI platforms with a semantic layer (often using dimensions, metrics, fields) that allow for a limited set of operations (e.g., Tableau, Looker, Zenlytics)
High-level, vertical-specific BI products that handle the entire stack—from data collection to report generation—with minimal setup (e.g., Google Analytics, Amplitude, AppsFlyer)
Generic BI Platforms
Products using a semantic layer make up most of the data analytics landscape. This includes both traditional incumbents like Tableau, PowerBI, Looker, and even “newer” entrants like Zenlytics, Omni, LightDash, GoodData, and ThoughtSpot.
These platforms generally require data to be structured in a specific way and often rely on data scientists to prepare it by writing code. Once the data is formatted correctly, users can create charts, dashboards, and more. However, even after formatting, the operations available remain limited by the semantic layer. Accessing data in JSON fields, multiple aggregates, filtering using an “or” condition, transforming text to lower- or uppercase, etc. are often simply not supported. This means that there’s no single “correct” data format that answers every important question.
If you need an unsupported operation to answer a question, you need to write code.
Simply allowing users to ask questions in plain English doesn’t fundamentally change a product’s ability to provide the correct answer. For example, even if data in PowerBI is set up perfectly to display 1) how many unique users pressed a specific button and 2) how many times that button was pressed, it might still be impossible to determine the average button presses per user without multiple aggregations—something beyond PowerBI’s capability.


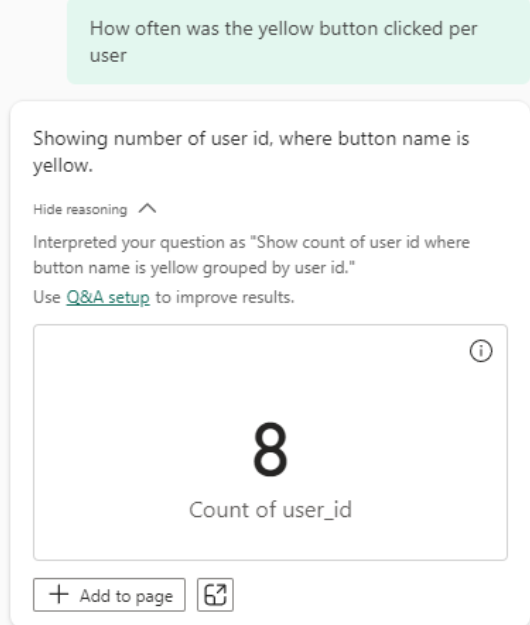
This specific example might be easier in other tools, but the fundamental issue remains: every single BI product using a semantic layer is very limited in what it can do vs. what a data scientist could do with code. “How often is a button pressed per day on average” is not some obscure, one-off metric - it fundamentally affects how products are designed.
This highlights the fatal flaw of most data products - almost every unique problem needs data to be formatted in a specific way - making data scientists’ bandwidth to write code a bottleneck for the entire organization.
All of this severely limits the usefulness of these tools: only employees with access to data scientists can get their questions answered. Instead of adding value to every employee of the company, those tools add value to every data scientist.
This is especially clear when you look at Tableau’s pricing:


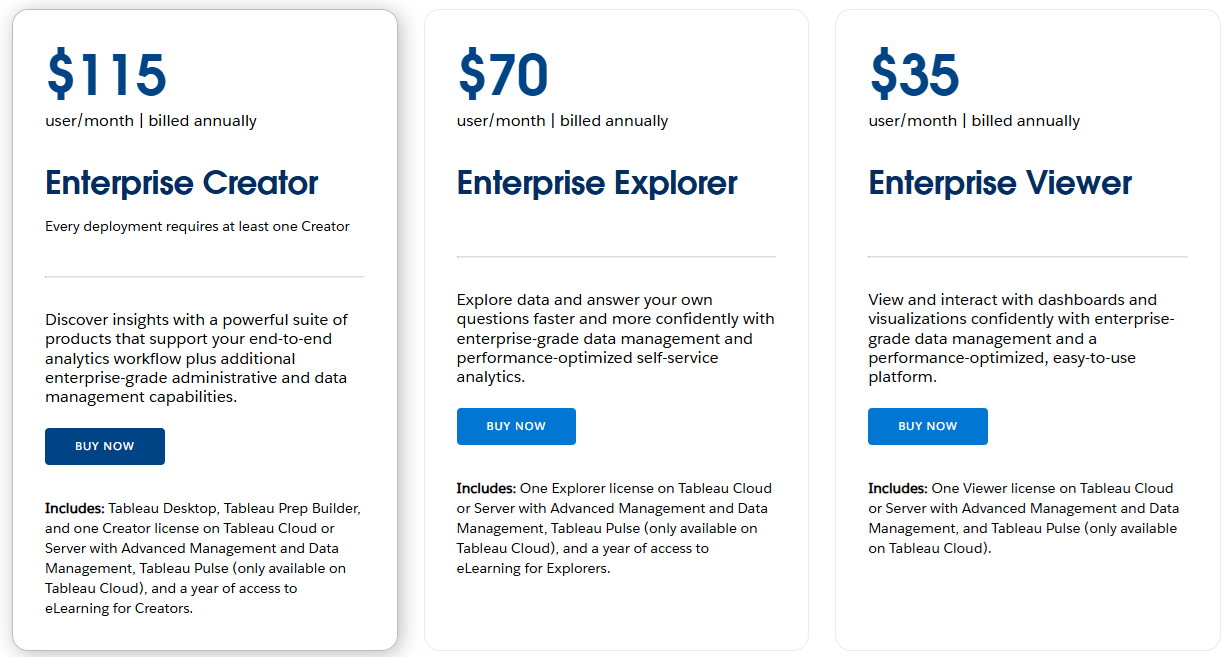
Tableau’s pricing scheme clearly demonstrates diminishing returns for different user tiers. Most employees end up in a hidden $0 tier: they simply don’t use the product at all.
Vertical-Specific BI Tools
Vertical-specific tools excel by focusing on one thing and doing it well. They don’t usually require a data engineer for setup—just add tracking code, and dashboards populate automatically with battle-tested metrics (e.g. Google Analytics).
However, tracking new metrics is nearly impossible, and the data collected is siloed and inflexible, making it challenging to integrate with other information, like a product database. Extracting data often requires expensive services or significant engineering effort, which isn’t included with the product.
Here, AI / natural language can facilitate access to existing metrics, but if a user asks for something even slightly different than what the tool already provides, it won’t be able to answer. Unlike generic BI platforms, most vertical-specific BI tools don't even advertise GenAI capabilities. See the difference between GA and Tableau's websites:





So what does work?
A common theme with BI tools is the need for data to be shaped in a specific way. Every product mentioned here—Tableau, Amplitude, Google Analytics, PowerBI, Zenlytics, and Tellius—requires data in a format specific to its intended function. However, this is not how most valuable company data is generated.
Analytics data is often generated based on internal product data (e.g. shipping addresses, account settings, technical logs, user metadata), or it is generated by analytics code added to the product. This analytics code is a very low priority for most companies, so the data is often just saved as unstructured JSON events. That’s very efficient when building the product, but always requires reshaping after the fact.
Removing the need to manually “reshape” data specifically for analytics would add the most immediate value. Luckily, LLMs can be quite effective at this.
Generative AI changes this
GenAI changes the landscape. Large language models can generate code (e.g. SQL, Python, R) to instantly transform data into formats suitable for specific business problems. This eliminates the need for a data scientist to code every solution beyond the limits of a semantic layer, and in turn allows organizations to increase their analytics capabilities without a corresponding increase in data science resources.
A GenAI powered analytics product that can transform data in all the ways that a data scientist can is actually free to deliver on the promise of “natural language analytics.” This is because it has all the tools necessary to answer any question a user might have, not just a specific set of questions for a certain group of users.
If every single person in an organization can ask questions directly relevant to their job and immediately get accurate results, then finally data products can deliver on their longstanding promises.
Of course, the solution is not as easy as “just ask the LLM to write some code” - there are many things to consider and it’s something we’ve spent the past two years building at Datawisp. But how to correctly leverage genAI for data analytics is its own topic that we may write about in the future.
Why Legacy BI Tools Will Struggle
Products built before the advent of LLMs fundamentally aren’t well positioned to take advantage of this technology. They essentially have one of three bad options:
Use text-to-SQL directly, bypassing the semantic layer: While easy to implement, this approach has downsides: lack of access control, SQL dialect variations, limited interpretability for non-coders, potential security risks, …
Rely on the existing semantic layer: this severely restricts the LLM to current capabilities, limiting the fulfillment of the “ask any question” promise.
Build something entirely new in parallel: Starting from scratch is daunting. It requires redirecting engineering resources from current revenue-generating products to a project that may take a year or two to show results. This is challenging, especially for teams trying to hit their next revenue milestone.
Recently, Tesla exemplified this approach by discarding over 300,000 lines of code from its Full-Self-Driving (FSD) system and replacing it with neural networks in FSD v12. The update, which was widely praised, delivered smoother, safer, and more adaptable performance. However, few companies are willing to take such a bold step.
Relying on the existing semantic layer is the approach chosen by most current-gen BI tools, with limited success. While it does work in the short term to answer basic questions, improvements in the underlying LLMs will leave these tools behind as their semantic layer grows ever more limiting.
Next-gen BI tools are already surpassing tools using that approach, and the gap will only widen.
TLDR
Most products today, even if they use AI, rely on an extremely limiting semantic layer
These products are very expensive in data science resources to maintain, which prevents them from scaling to everyone in the organization
Only GenAI native data products that can freely transform data can deliver on the promise of “natural language analytics”